
Mise à jour au 21 juillet 2025
« Nous entrons dans l’ère de l’expérience. »
— David Silver & Richard Sutton, 2025
Kimi K2 Depuis sa publication surprise le 11 juillet 2025, Kimi K2 de Moonshot AI est devenu, en l’espace de dix jours, la nouvelle coqueluche des développeurs, des chercheurs et des entreprises à la recherche d’un large language model (LLM) ultra-performant, véritablement open-source et étonnamment peu coûteux à l’usage.
Dans cet article au format long, nous allons décortiquer :
- Les fondements scientifiques qui font de K2 une avancée majeure dans les lois d’échelle de l’IA.
- L’architecture technique (MoE 1 T, MuonClip) et les benchmarks détaillés.
- Les cas d’usage concrets : génération de code, agents autonomes, analyse de documents longs, etc.
- Les guides pratiques : installation locale, fine-tuning, déploiement sur cloud (Groq, Unsloth).
- Les limites et les risques à surveiller.
- Une roadmap prospective de l’écosystème K2.
1. Pourquoi Kimi K2 changeur la donne : la fin du “fossile humain”
1.1 Le problème du data wall
Ilya Sutskever (OpenAI) le formule brutalement : les données humaines sont un carburant fossile fini. L’augmentation exponentielle du compute rend l’apprentissage préalable (pre-training) dépendant d’une ressource rare : les tokens humains labellisés.
Kimi K2 Moonshot AI répond par deux leviers :
- Token-efficiency : chaque token doit produire plus d’intelligence.
- Auto-supervision avancée : le modèle apprend principalement de ses propres interactions (RL + récompenses automatiques), réduisant la dépendance aux annotations humaines.
1.2 Le paradigme “Agentic Intelligence”
Kimi K2 n’est pas qu’un LLM conversationnel ; il est conçu pour agir : appeler des outils, exécuter du code, planifier des taches complexes et même se corriger lui-même. C hne ce que Moonshot lire lire on appelle Ouvrir état agentique Intelligence.
2. L’Architecture et les innovations techniques
2.1 Vue d’ensemble chiffrée
| Caractéristique | Valeur | Commentaire |
|---|---|---|
| Architecture | MoE (Mixture of Experts) | 384 experts, 8 actifs par token |
| Paramètres totaux | 1 000 milliards (1 T) | Tous stockés mais épars |
| Paramètres activés | 32 milliards | ≈ coût inférence GPT-3.5 |
| Contexte | 128 k tokens | Suffisant pour >300 pages A4 |
| Optimiseur | MuonClip (vs AdamW) | Stabilité + efficacité |
| Dataset pré-training | 15,5 T tokens | Multilingue, code, math, web |
2.2 MuonClip : stabiliser Muon à l’échelle
Kimi K2 L’optimiseur Muon offre déjà 1,3× de gain par rapport à AdamW sur les benchmarks internes. Mais à grande échelle, il provoque des explosions de logits d’attention.
La solution qk-clip rescale dynamiquement les matrices Query & Key après chaque step :
qk_scale = max(1, max_logit / threshold)
query *= qk_scale
key *= qk_scaleRésultat : zéro spike de perte sur 15,5 T tokens, sans dégradation downstream.
2.3 Choix MoE
- Sparsité accrue : 8/384 experts actifs ⇒ moindre latence GPU.
- CPU-offload : couches feed-forward des experts inactifs sur RAM, réduisant la VRAM requise de 70 %.
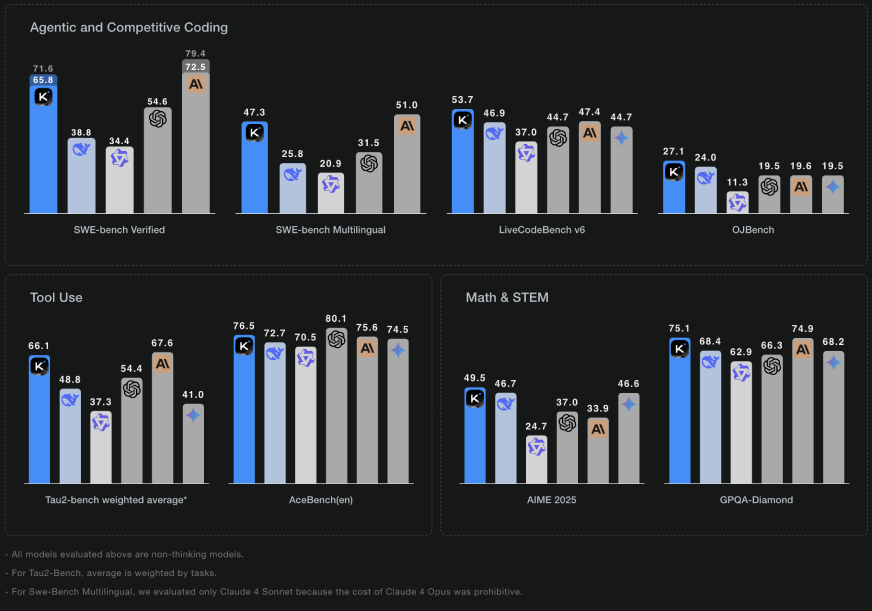
3. Les Performances mesurées
3.1 Benchmarks clés (juillet 2025)
| Benchmark | K2-Instruct | GPT-4.1 | Claude Opus 4 | Remarque |
|---|---|---|---|---|
| LiveCodeBench Pass@1 | 53,7 % | 50,2 % | 52,1 % | Code généré en un seul essai |
| SWE-Bench Verified | 65,8 % | 63,4 % | 64,0 % | Résolution de bugs GitHub réels |
| MMLU (5-shot) | 89,5 % | 88,9 % | 89,2 % | Connaissances générales |
| Tau2 Retail Tasks | 70,6 % | 68,0 % | 69,5 % | Scénarios e-commerce |
Kimi K2 surpasse donc tous les modèles propriétaires dans les tâches de codage, tout en restant open-source.
3.2 Coût & latence
- Prix Groq Cloud : 0,07 $ / 1 M tokens (input) – 10× moins cher que GPT-4o.
- Débit Groq : >800 tok/s en int8 sur L40S.
- Inférence locale RTX 4090 : 27 tok/s avec llama.cpp + 35 couches GPU.
4. Cas d’usage concrets & snippets
4.1 Agent autonome avec appels d’outils
Exemple : assistant RH qui récupère le profil d’un candidat, lance un test technique puis envoie un résumé par mail.
import os, json, requests
from openai import OpenAI
client = OpenAI(
base_url="https://api.groq.com/openai/v1",
api_key=os.getenv("GROQ_API_KEY")
)
tools = [{
"type": "function",
"function": {
"name": "fetch_github",
"description": "Récupère les 10 derniers repos d’un utilisateur GitHub",
"parameters": {
"type": "object",
"properties": {
"username": {"type": "string"}
},
"required": ["username"]
}
}
}]
def fetch_github(username: str):
url = f"https://api.github.com/users/{username}/repos?per_page=10"
return requests.get(url).json()
tool_map = {"fetch_github": fetch_github}
messages = [
{"role": "system", "content": "Tu es un recruteur technique."},
{"role": "user", "content": "Analyse le profil GitHub de 'michaelfromyeg'."}
]
# Boucle d’agent
while True:
resp = client.chat.completions.create(
model="moonshotai/kimi-k2-instruct",
messages=messages,
tools=tools, tool_choice="auto"
)
msg = resp.choices[0].message
messages.append(msg)
if not msg.tool_calls:
break
for tc in msg.tool_calls:
res = tool_map[tc.function.name](**json.loads(tc.function.arguments))
messages.append({"role": "tool", "tool_call_id": tc.id,
"name": tc.function.name, "content": json.dumps(res)})
print(msg.content)4.2 Génération de code long contexte
Kimi K2 peut digérer 100 k tok de documentation legacy et générer une refonte complète. Exemple prompt :
Voici 5000 lignes de code COBOL. Propose une architecture micro-services en Go,
respecte les règles métier, écris les tests unitaires et un Dockerfile.
4.3 Analyse financière multi-documents
Chargez 20 rapports annuels (PDF) → Kimi K2 extrait les KPI, construit des nations unies tableau comparatif et génère des nations unies résumé exécutif.
5. Guide de démoiement pas-à-pas
5.1 Local (llama.cpp)
- Téléchargez les poids GGUF :
wget https://huggingface.co/unsloth/Kimi-K2-Instruct-GGUF/resolve/main/Kimi-K2-Instruct-UD-TQ1_0-00001-of-00005.gguf- Lancez :
./llama-cli \
--model Kimi-K2-Instruct-UD-TQ1_0-00001-of-00005.gguf \
--n-gpu-layers 35 --ctx-size 32768 --temp 0.6 -cnv(Ajustez n-gpu-layers selon votre VRAM).
5.2 Fine-tuning avec Unsloth
Unsloth propose des notebooks ready-to-use :
from unsloth import FastLanguageModel
model, tokenizer = FastLanguageModel.from_pretrained(
model_name = "unsloth/Kimi-K2-Instruct",
max_seq_length = 32768,
load_in_4bit = True,
)
trainer = SFTTrainer(
model = model,
train_dataset = dataset,
dataset_text_field = "prompt",
max_seq_length = 32768,
)
trainer.train()
5.3 Déploiement serverless sur Groq
curl https://api.groq.com/openai/v1/chat/completions \
-H "Authorization: Bearer $GROQ_API_KEY" \
-d '{
"model": "moonshotai/kimi-k2-instruct",
"messages": [{"role":"user","content":"Crée un CRUD Express.js avec TypeScript."}]
}'6. Limites, éthique et risques
| Risque | Statut | Recommandation |
|---|---|---|
| Hallucinations | Faible mais présent | Toujours exécuter le code généré dans un bac à sable |
| Fuites de données | Aucune preuve à ce jour | Ne pas intégrer de PII dans les prompts |
| Biais culturels | Benchmarks majoritairement anglophones | Fine-tuner sur corpus local |
| Jailbreaks | Tests communautaires en cours | Filtrer les outputs via modèle secondaire |
| Licence | Apache-2.0 avec clause “Open Use” | Usage commercial autorisé, redistribution libre |

7. Feuille de route communautaire & perspectives
- Juillet-Août 2025 : sortie des adapters LoRA français, allemand, japonais.
- Septembre : support natif des images (Kimi-K2-Vision).
- Q4 2025 : version “edge” 4-bit <8 GB pour smartphones.
- 2026 : architecture MoE-Mamba hybride visant 10 M tokens de contexte.
Moonshot ouvre également son Kimi K2-Agent-Hub, un registre d’agents open-source où la communauté pourra partager des skills réutilisables (booking, BI, DevSecOps…).
Conclusion : pourquoi vous devriez essayer K2 dès aujourd’hui
- Performance SOTA en codage et raisonnement long.
- Coût 10× inférieur aux concurrents propriétaires.
- Open-source complet : poids, code, scripts de training.
- Écosystème mature : Groq, Unsloth, llama.cpp, Ollama.
En 2025, Kimi K2 n’est pas seulement un nouveau modèle ; il est le catalyseur d’un changement de paradigme vers des agents autonomes accessibles à tous.
Fork, codez, partagez — l’intelligence agentive est désormais entre vos mains.









